1. |
 |
A client contacts a random storage server to read or write a file. Clients get a full list of replicas when opening a file from which they can choose a storage server.
|
2. |
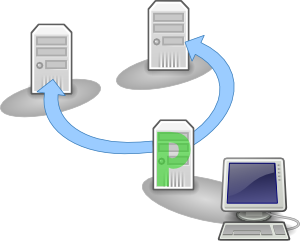 |
The storage server coordinates the primary lease with the other storage servers and becomes the Primary replica for that file. The other replicas act as backups.
Once a server has become primary, it brings the replicas to a consistent state by executing the so called Replica Reset. It collects the file's state from the other storage servers and calculates the correct state. If necessary, the replicas exchange data to bring themselves up-to-date.
|
3. |
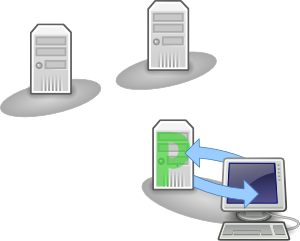 |
The client can now execute operations on the file. A read, as shown in the diagram, is executed locally without communication with other replicas. With the replica reset, the primary can guarantee that it has the latest state of the file on disk.
|
4. |
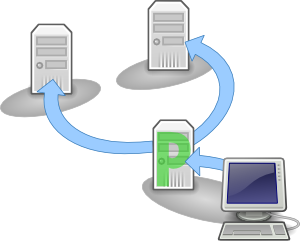 |
Write operations executed by the client are applied first locally on the primary server. Then the primary sends the updates to the backups. When the backups have finished the write, the client receives the acknowledgment.
|
5. |
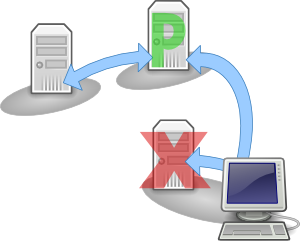 |
Should the primary server fail or get disconnected, the client will try to contact the other storage servers. Once the storage servers see that the primary has failed, they will elect a new primary. The new primary will execute the primary reset as in step 4. The client does this transparently, i.e. applications and users will only notice a delay but they won't see any errors.
|

